
AI, Machine Learning and neural networks explained
| Sieuwert van Otterloo |
Artificial Intelligence
This summer, we were invited by the Utrecht University of Applied Sciences to explain artificial intelligence, machine learning and neural networks.In a one hour webinar, we used python to train an actual neural network, showed the audience what can go wrong and how to fix it, with time left for discussing the ethical implications of using AI in the real world. In this article we summarise the webinar and conclude with links to the webinar slides, the webinar code and suggestions for additional resources.
Artificial Intelligence explained
Artificial Intelligence (AI) is a collection of tools and techniques that can be used to let computers do challenging tasks. AI started in the 1950, but for a very long period it was a research field without practical applications, because computers were not powerful enough to handle large amount of data. Since 2010, AI has experienced a breakthrough. There have been several computer science advances that have led to a break through and any computer scientist can now implement their own AI. This breakthrough has led to new opportunities, but also to new risks. AI algorithms can make mistakes, and such mistakes can lad to serious harm or damages: cars can crash, patients can be misdiagnosed, people’s privacy can be violated and people can be unfairly excluded based on race and appearance. It is therefore important to teach anyone working with AI what AI is, how it works and what mistakes are likely to happen when using AI.
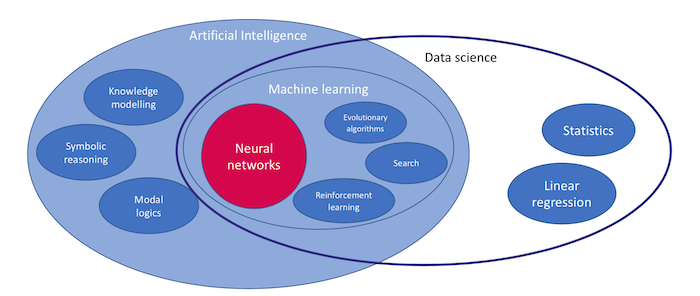
In our webinar, we explained AI by looking in detail at one of the most popular AI tools: neural networks. As you can see in the diagram above: neural networks are a class of machine learning algorithms.
Machine learning is an important subfield of AI, and is also an important subfield of data science. If you understand the benefits and risks of neural networks, you can understand common AI risks (such as described in this article on AI risks) and you can make better decisions on how to use AI.
What are neural networks?
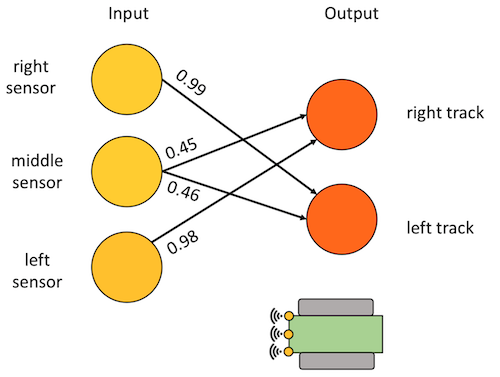 Neural networks are a way to transfer inputs into outputs. The way neural networks work is inspired by biology. Our nervous system consists of nerve cells. Each cell can be activated or not (e.g. the cells in our eyes are activated by the light that that reaches our eyes). Activated nerve cells send signals to other nerve cells through their connections. How this happen is determined by how each connection is formed. The nerve cells in our muscles act as output cells: if they get a signal, the muscle moves.
Neural networks are a way to transfer inputs into outputs. The way neural networks work is inspired by biology. Our nervous system consists of nerve cells. Each cell can be activated or not (e.g. the cells in our eyes are activated by the light that that reaches our eyes). Activated nerve cells send signals to other nerve cells through their connections. How this happen is determined by how each connection is formed. The nerve cells in our muscles act as output cells: if they get a signal, the muscle moves.
Artificial neural networks also have input cells and output cells. In this illustration in this paragraph, a very simple neural network is shown with three input cells (left) and two output cells (right). The input cells can see light, and they send signals to the output cells that are connected to the wheels of the robot. Each connection has a weights: from 0.99 to 0.45. A stronger weight means that the connection works better.
The behaviour of the robot is determined by the weights of the neural network. We can train the neural network by giving it specific inputs and outputs, and change the weights so that the required output happens. Once the neural network is trained, the connections can be fixed and the robot can be set loose in the real world. In this case, the robot will drive around and follow lights. This robot will not show very complicated behaviour, since the neural network is small and simple. A different robot with more inputs, more outputs and more neurons, could learn very complicated tasks.
Neural network and image recognition
Image classification is a common machine learning task. The goal of the task is to determine various properties or features of images. This means that we will use images as input for our neural networks, and will train the neural networks for recognising what they see in the images. The image below shows how neural networks for image recognition works.

Each image consists of separate pixels. In this case there are 20 input neurons in a 4 by 5 grid. We can show this simple network images of digits. In the example below, an image that looks like the digit ‘2’ is shown and we would like to hear from our neural network which digit is shown. We have therefore given the neural network ten output digits: one for each possible digit. This network has no direct connection between input and outputs, but there is an intermediate layer of neurons (only one neuron from this layer is shown). This is called a ‘hidden layer’ since the neurons in this layer are not input neurons and not output neurons. In this case, all pixels on the bottom get a lot of light. This means the input shown could be a “2”.
Training and testing neural networks
 This example shows that you can choose the number of neurons and layers for a specific image recognition tasks. AI engineers call this selecting the right ‘network topology’. Once you have chosen a topology, you have to find the right weights of all the connections between the neurons. The great thing about machine learning is that the AI engineer does not have to do this herself: There are algorithms that can do the hard work. The only thing that the AI engineer has to do is to present the neural network with training data: selected images for which the correct answer has already been determined. The algorithm can then be trained by the computer to give the best possible output for each image in the training set. Once the training is completed: the algorithm is tested on a new test set of images. The test set consists of images the algorithm has never seen before. If the neural network scores ‘good enough’ on the test set, the AI engineer’s job is done: we have a well trained neural network that can do whatever tasks it is supposed to do. Often however, the score is not yet good enough and the AI engineer has to get back to the drawing board. She can change the topology( e.g. add more neurons), or collect more data and retrain and retest. Getting neural networks is hard work. However: there is no coding involved. The neural network code and training algorithm stays the same. All improvements in performance are achieved by training and testing, as shown in the diagram below.
This example shows that you can choose the number of neurons and layers for a specific image recognition tasks. AI engineers call this selecting the right ‘network topology’. Once you have chosen a topology, you have to find the right weights of all the connections between the neurons. The great thing about machine learning is that the AI engineer does not have to do this herself: There are algorithms that can do the hard work. The only thing that the AI engineer has to do is to present the neural network with training data: selected images for which the correct answer has already been determined. The algorithm can then be trained by the computer to give the best possible output for each image in the training set. Once the training is completed: the algorithm is tested on a new test set of images. The test set consists of images the algorithm has never seen before. If the neural network scores ‘good enough’ on the test set, the AI engineer’s job is done: we have a well trained neural network that can do whatever tasks it is supposed to do. Often however, the score is not yet good enough and the AI engineer has to get back to the drawing board. She can change the topology( e.g. add more neurons), or collect more data and retrain and retest. Getting neural networks is hard work. However: there is no coding involved. The neural network code and training algorithm stays the same. All improvements in performance are achieved by training and testing, as shown in the diagram below.
If you have ever driven in a Tesla, you may have noticed that any Tesla has many camera’s and sensors, and that the care is continuously collecting information while driving. Tesla is using image recognition and machine learning to develop selfdriving cars. The neural networks involved are very complex, but the principle of data collection, training and testing is the same. You can learn and see more of their approach in this talk by Andrej Karpathy, director of AI at Tesla (link to video).
One interesting consequence of the machine learning approach is that the Tesla engineers believe in, or at least work towards, ‘Operation Vacation’. If the machine learning process can be automated completely, the engineers can go on holiday, while the AI keeps improving: every week data is collected by all Tesla cars, the same neural network is trained using the new data, and a better neural network will emerge without any effort by the human engineers. This ambition shows that power of machine learning over traditional programming. Please note that ‘Operation Vactation’ is still a pipe dream. Making neural networks is hard work, often with disappointing results. There is no coding involved but a lot of data collection, data checking and reviewing test results.
Image recognition on cars
In our webinar we trained a neural network to work on images of cars. We used an existing dataset by Jonathan Krause, Michael Stark, Jia Deng and Li Fei-Fei. This dataset is free but you should quote the paper ‘ 3D Object Representations for Fine-Grained Categorization’ when using this dataset.
We defined a new task, called car direction. We identified six directions, as shown below.

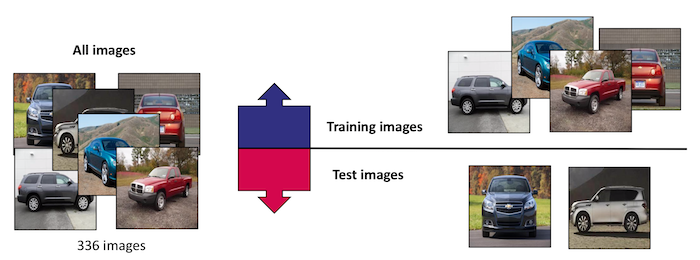
Each photo we selected shows one car facing in one of each direction. The neural network was trained to indicate in what direction the car is facing. This task is simple for humans, but challenging for computers due to the diversity in cars. Our code and data can be found on Github as Cars-NeuralNetwork. Each image was rescaled to 256×256 pixels, since neural networks work best when the image size is fixed. We started with 336 images, and split these images in 270 training images, and 66 test images.
We started of with a simple neural network topology with 3 hidden layers. Our code was written in python, using the Keras neural network library. Our initial attempt was not successful: initially the algorithm only scored 30-40% correct on the test set. This is better than random, but one can imagine that such a score is not good when using it in a selfdriving car. The car would crash in minutes. During the workshop we used the training loop shown above a few times: We choose a better neural network topology with more layers, and then added more images. The table below shows the symptoms that occur often during machine learning, and what can be done by the AI engineer in the next training round. Some of the steps involve changing the network or the training setup. At some point however, changing the network or training will not help and more data is needed. Neural networks are only as reliable as the data they get. If the data is imperfect, biased or discriminatory, the neural network will also be imperfect, biased or discriminatory.

In general, neural networks become more reliable if more data is available. Collecting more data is however a challenge. Our best topology on the best data set classifies 80% of images correctly. This is an impressive result, but not perfect. This is quite common in Ai and machine learning: There almost never is time and data to make algorithms 100% accurate. Most AI applications make mistakes and one should not expect AI decisions to be perfect.
Conclusions and next steps
If you are considering to use AI, machine learning or neural networks in your organisation, it is important that everyone understands that training process, the role of data and the limited accuracy of AI solutions. Most AI systems make mistakes and have biases. Artificial Intelligence should be used with care.
If you want to know more about machine learning, we recommend the Python Data Science handbook by Jake VanderPlas. We also highly recommend the book ‘R for Data Science‘. Our cars image classification code is based on this fashion neural network example by François Chollet. This tutorial is included in the Tensorflow documentation.
There is a lot of interesting research into the responsible use of AI and ethics of AI, check this article on algorithmic bias and how algorithms might discriminate against women and people of color. This article describes many AI-specific risks and examples on how there occur. One Dutch initiative to prevent AI risks to occur is the AI Impact Assessment.
The webinar was made by Bert Wassink from Dataworkz, Joost Krapels from ICT Institute, Sieuwert van Otterloo from ICT Institute and Utrecht University of Applied Sciences, and Stefan Leijnen from Utrecht University of Applied Sciences. Sieuwert and Stefan work at the AI research group. In this research group, we look at the responsible use of AI in the creative and media sector, fin-tech sector and other AI applications. We sometimes have research internships (this is an example of a past research internship into facial recognition). The slides of the webinar can be found here.
At ICT Institute, we provide training and advice on AI-related matters. If you want an AI system te be assessed, or are looking for training in the responsible use of AI, want to train your organisation in using machine learning and data science, or have an interesting machine learning challenge, feel free to contact us.
Dr. Sieuwert van Otterloo is a court-certified IT expert with interests in agile, security, software research and IT-contracts. He is a also an ISO 27001 and NEN 7510 auditor and AI researcher.