
Comparing cloud AI services against open source libraries for face detection
| Sieuwert van Otterloo |
Artificial Intelligence
Research
The three large cloud companies Google, Microsoft and Amazon offer cloud services for many AI tasks. Using these services has practical benefits but also strategic risks: when using a service, you have less control over your AI use. In order to gain insight into the pros and cons of AI services, Elif Kalkan has done a comparison of three services and three open source libraries for face detection.
What is face detection?
Face detection is a common task in machine learning where the computer must find faces in photos. The computer is given a photo and must place boxes around all faces in the picture. Face detection is an important tasks since it is used in anonymisation, identification, security monitoring and camera control. The image below shows what this looks like. The computer has identified five faces in this photo.

Face detection is a solved machine learning problem: There are multiple good open source libraries that often face detection and various tests sets for training and testing facial detection. In practice, performance depends on the circumstances: results are better with better lighting and worse with poor lighting or lower quality cameras. Given the existence of multiple good libraries, it is not necessary for companies to develop face detection. Any developer can simply call a service or a library. Companies do need to test the performance for their specific situation.
Risk and benefits of cloud services
Cloud computing means that users use centralised computer resources that are managed by a cloud provider, without users knowing exactly where the computers are or how they are configured (the computers are said to be part of ‘the cloud’). The benefit of cloud computing is that cloud providers enjoy benefits of scale in managing the resources. They can also share resources between users who may need them at different times, only charging them for actual use. In theory, the performance of computer programs is not affected by the location of the computers. Any program that can work locally can also work in the cloud. In practice however there are important differences between using the cloud or running locally. The potential benefits of the cloud are as follows:
- Better results through data: Cloud providers are not very transparent about which algorithms and libraries they use. They could be using open source libraries. They may have invested in their own unique algorithms. It is possible that they use more data and thus get better results.
- More resources: Cloud providers could use larger or faster computers for their algorithms that developers have locally, leading to higher performance or faster response times.
- Ease of use: When using a library, one has to decide how to reply the library and perhaps make configuration choices. Cloud services are already configured and can be used directly.
The potential risks of using cloud algorithms are:
- Sharing personal data. To use a cloud service, one must share photos with the cloud service. It is possible that the cloud service logs and analyses the use, stores the photos for their own purposes and might leak the photos later on. Sharing photos with a cloud provider would require a data processing agreement and perhaps a Data Protection Impact Analysis if sensitive images are used.
- No ability to innovate: You can only use the service as-is, and not improve the service based on your own datasets. Developers with unique needs (e.g. recognise animal faces or recognising faces from night vision cameras) will probably not get good results from standard services.
- Dependence on network performance. To use cloud services, the data must be uploaded to the cloud first. Certain applications, e.g. use in automated driving, would require a local solution.
Research goal and approach
The main purpose of the thesis research by Elif Kalkan was to determine the differences in performance and ease of use of different cloud services and local libraries. The following services were tested:
- Amazon Rekognition API
- Azure Face API
- The Google Cloud Vision API
All of these are collections of pre-trained machine learning algorithms that can be used without the need for data collection of training. The only practical problem in using these algorithms are related to security: one needs to understand how to connect to the services without being blocked by the cloud security controls.
The performance of these services was compared to three open source libraries: OpenCV (https://opencv.org/), DLib (http://dlib.net/), and a pretrained model using PyTorch(https://github.com/timesler/facenet-pytorch).
The algorithms were compared by using them to detect faces on a dataset with known answers. The results of each service were compared to the known answers. This was done by computing overlap: any box that overlapped 50% or more with a known correct answer was counted as correct. By counting correct, missing and incorrect boxes one can compute overall accuracy for each algorithm. To make the task more challenging, the services and libraries were tested on the original, high quality images but also on images with added noise. All images are from the WIDER data set. From this dataset, images with mostly frontal face photos were used.
Face detection accuracy and speed
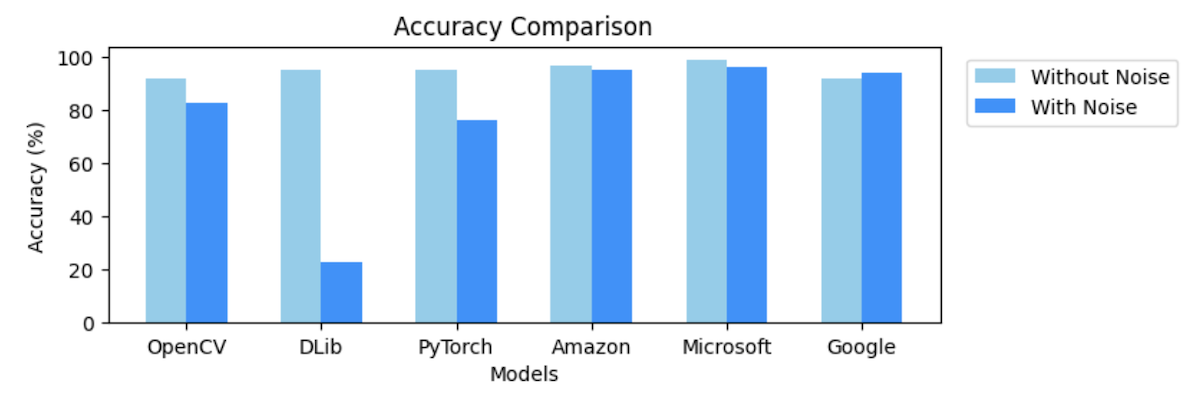
All libraries and services have more than 90% accuracy on the original high quality photos, with the cloud services doing better than the libraries. It seems that there are indeed benefits of scale in training AI. A peculiar result is that the google service was oversensitive, and identified faces that were not identified by the makes of the test set. When manually checking the differences, the google results were accurate.
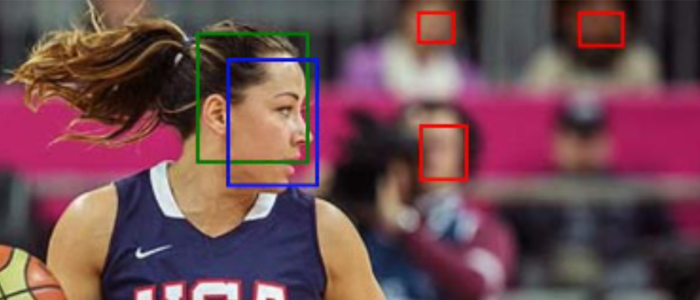
 The image on top of this article shows this result: the red boxes are faces detected in the blurred background that were identified by Google but not by the other services. Whether this hypersensitivity is useful in practice depends on your situation, but it is impressive.
The image on top of this article shows this result: the red boxes are faces detected in the blurred background that were identified by Google but not by the other services. Whether this hypersensitivity is useful in practice depends on your situation, but it is impressive.
The open source libraries OpenCV, DLib, and PyTorch all use a different method for face detection, and handle noise differently. DLib especially could not handle noise. The accuracy dropped from 95% TO 23%. If your images are noisy, DLib is not a good choice. This finding illustrates that one must always test AI applications in practice.
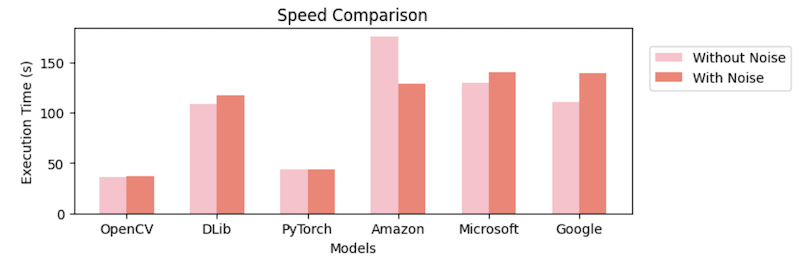
The execution speed of the libraries was much better than that of the cloud services. This is probably due to the fact that sending images to the cloud services takes time.
Conclusions and further reading
Modern cloud platforms offer AI services that are at least as good and possibly better than available open source libraries. In cases were privacy and network dependence are not a problem, developers can use AI cloud services. In cases where privacy, data protection, execution speed or network indigence are concerns, one should consider the pre-trained algorithms in source libraries. In each case, carefully test the performance on your actual data: adding noise can severely impact the results. If you are interested in the full results including the code examples, you can download the thesis here: Exploring Face Detection Models: A Comparative Analysis of Local-Based and Cloud-Based Approaches. (Kalkan, E – Amsterdam 2023).
Dr. Sieuwert van Otterloo is a court-certified IT expert with interests in agile, security, software research and IT-contracts. He is a also an ISO 27001 and NEN 7510 auditor and AI researcher.