
Summer school AI and machine learning
| Sieuwert van Otterloo |
Artificial Intelligence
In June 2021 we taught a one week summerschool at the Utrecht University of Applied Sciences. In this article we outline how this week was set up and share some of the lecture material. (note: for the 2022 edition, check this article on the Utrecht Housing Dataset)
The goal of the summer school was to enable people with a general university background to understand multiple AI techniques, be able to use them in practice and also understand the risks and limitations. Luckily, many good AI algorithms are easily accessible in form of standardised libraries. With the help of the programming language python, Jupiter notebooks and several python libraries anyone can train an AI system: using AI is no harder than driving a car: anyone can learn it with some hours of training. Using it wisely however is a challenge even for major companies.
Course setup – core components
The course consisted of five days, with two focus that we believe is a good way to learn data science. The main topics are:
- Data exploration and visualisation
- Decision trees and regression
- Prediction with neural networks
- Image recognition
- Evolutionary algorithms
The main advantage of a five day course is that you can actually “do AI”. In these five days, people analysed actual data and created and tested multiple algorithms.
The main lectures present all days were Sieuwert van Otterloo and Stan Meyberg. Additional guest lectures were delivered by Stefan Leijnen, Ouren Kuiper, Piet Snel and Roland Bijvank. The modules were chosen with an eye towards human centered AI: the responsible use of AI in a way that helps people.
Data exploration and visualisation
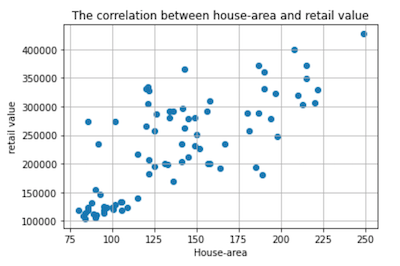 In this course we used an artificial data set that can be used for predicting house prices (see download here). Our goal is to use neural networks to do this. However, before you apply any algorithm, you should first analyse and understand the data yourself. This is called data exploration. In the data exploration phase you should look at each available feature to see if it is actually useful and how it is encoded, and at each data point to make sure it contains sensible values. Using python and various libraries, it is easy to visualize data. The example shown here is a scatterplot that shows the entire data set. The variable we are trying to predict is retail value. This plot shows that house area has some correlation to retail value, so it should be used as input. From the plot you can also see what minimum, maximum and average values are for both retail value and House-area. You should make plots for all variables, and study these plots to understand the data. In real life, you would use these plots in interviews with domain experts in order to understand the data and the problem we are trying to solve.
In this course we used an artificial data set that can be used for predicting house prices (see download here). Our goal is to use neural networks to do this. However, before you apply any algorithm, you should first analyse and understand the data yourself. This is called data exploration. In the data exploration phase you should look at each available feature to see if it is actually useful and how it is encoded, and at each data point to make sure it contains sensible values. Using python and various libraries, it is easy to visualize data. The example shown here is a scatterplot that shows the entire data set. The variable we are trying to predict is retail value. This plot shows that house area has some correlation to retail value, so it should be used as input. From the plot you can also see what minimum, maximum and average values are for both retail value and House-area. You should make plots for all variables, and study these plots to understand the data. In real life, you would use these plots in interviews with domain experts in order to understand the data and the problem we are trying to solve.
After exploration of the data set, you can drop certain columns, re-scale other columns or transform columns to make them understandable for algorithms.
Decision trees and regression
A lot of reliable real world AI solutions are not based on advanced algorithms such as neural networks. Instead they are based on proven data science techniques that are reliable and easier to validate. Linear regression and decision trees are such techniques.
Linear regression is an optimisation techniques where the effect of different inputs is added up. The result is a model that is easy to understand and can yield good results with suitable inputs. In the case of house prices, linear regression works well on lot-area, house size and number of bathrooms. It does not handle the location very well.
Decision trees are models that use a series of decisions to cluster data points into similar groups. Making an optimal decision tree is a challenge that requires a computer. Reading and using a decision tree is however quite easy. With an increased need for transparency, we expect decision trees to make a comeback as an example of explainable algorithms.
Prediction with neural networks
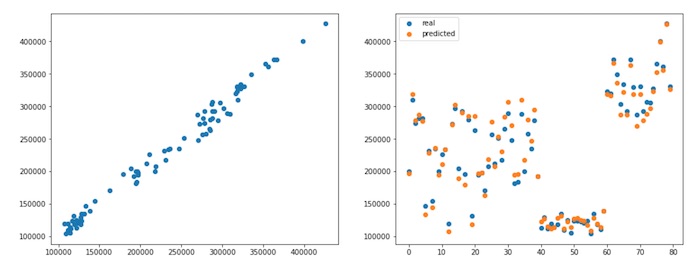
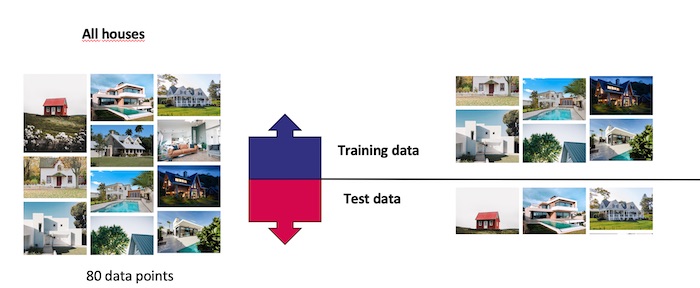
Neural networks (NNs) are one of the best ‘general purpose’ AI solutions. A neural network is a very good “general problem solver”: you can train a neural network to solve many problems. The algorithm itself is versatile enough to give good results, provided you have enough data for training. In the course we trained different neural networks with different data sets in order to compare the results. An important concept is the idea of splitting data into train data and test data. Any algorithm must be tested using fresh data that was not used in training, to make sure it works well on new cases and not just old cases.
Image recognition
Images are one example of ‘rich media’: input data that is complex and detailed. Such data can be interpreted by neural networks, if you define a way to encode an image as a series of numbers. The process is the same as for non-image data: you need training data, test data, and you need to try different neural networks and compare results. A unique challenge for image recognition is that you need lots of data: since the neural networks working images are large, large sets of images are needed. Are images must be annotated / classified. This can generate a lot of work for students or other people. All images must be annotated for the property that you want the neural network to learn. This can be simple (is there a tree in the photo, color of the house) or very complicated (exact size, true value). In practice, getting AI to work is labor intensive. You need not only data scientists but also domain experts.
Evolutionary algorithms and decision trees
Evolutionary algorithms are a family of algorithms that are inspired by evolution and natural selection. Most evolutionary algorithms start with creating a population of randomly generated ‘solution candidates’. The solution candidates are selected or discarded based on how optimal they are, and new solution candidates are created by combining the existing solutions. We used evolutionary algorithm code from Robert Kuebler to solve the famous travelling salesman problem.
Additional topics
In addition to the main practical topics, five background topics have been explained and discussed:
- History of AI, including Alan Turing, and other classical AI examples
- AI and ethics (this includes playing the ‘serious game’ Ethics Inc, one of the hulpmiddelen voor verantwoorde AI)
- AI validation / medical AI, with practical advice how to do validation of algorithms
- AI and creativity by prof. Stefan Leijnen, including examples of generative AI and AI and humor
- Business process mining: how to interpret log data to identify process errors
Downloads and more information
In the spirit of creative commons and open source, we decided to share some of the material. You can use it as-is as self study.
- You can download the multiple choice exam to test your knowledge of AI and machine learning
- Day 1 slides with AI introduction and visualisation
- Day 2 slides with clustering, regression and ethics
- Day 3 slides with neural network examples
- The house price data file, available in the 2022 version from this page.
- The Jupyter notebooks with AI exercise from the lectures. They contain example code in python for the algorithms explained.
If you are a teacher or lecturer and would like source files, or the answer versions of the python files, please contact me (sieuwert at ictinstitute dot nl). if you would like to know more about applied AI research, please contact the AI research group at Utrecht Unversity of Applied Sciences.
Dr. Sieuwert van Otterloo is a court-certified IT expert with interests in agile, security, software research and IT-contracts. He is a also an ISO 27001 and NEN 7510 auditor and AI researcher.