
Access Management: an introduction
| Pavlo Burda |
Security

You can have the best XDR solutions out there, but if your data bucket is openly reachable online or a guest account is still active after years, these technological controls are not really protecting you. For instance, the top risks for web apps are broken access control and security misconfiguration. This is where IAM comes in.
Identity and Access Management (IAM) concerns the identification, authentication and authorization of users to access information assets. Imagine that you would like to retrieve cash at the ATM: identification happens when you insert your bank card, telling the machine “who am I, it’s my account”; authentication is the PIN, which is something only you know and it matches the bank records to say “it is really me”; authorization is everything else than you can do after the being authenticated like withdrawing cash, but only within an authorized amount, that is, your balance.
The good news is that the ISO 27001 standard gives you a clear set of controls to anchor the work to. This article walks through the IAM-related controls in ISO 27001 and translates each into what you should actually do on Monday morning. Rather than explaining what IAM is, this article it focuses on the organizational controls a infosec manager is typically asked to implement, review, and evidence to an auditor.
IAM in practice
Services that are not inherently public will require some sort of access management. It is not only users that log in to services like web sites, email servers or applications. Most of the internet infrastructure relies on a client-service paradigm where processes and applications communicate over the Service Oriented Architecture (SOA). Concrete examples are RESTful APIs when we use mobile and desktop apps and SOAP protocols for banking, payment gateways and billing calls for business processes.
To make the whole system secure, we need to manage access to such services. A typical setup for many organization was Active Directory: when an employee arrived in the morning and logged into a Windows workstation, the pc forwarded the request to a central domain controller which authenticated the session. Within the domain controller different users belong to different groups, like Finance and HR, with access to own resources on the local network, which was physically located at the company.
Current solutions
The current model shifted to a distributed and remote-first approach where cloud-based IAM solutions, like Entra ID, manage access by identity (rather than network). Every login is evaluated in real time against a set of conditional access policies that weigh who the user is, which device they are on, where the request is coming from, and how sensitive the resource being requested is. All resources like Microsoft 365, Workday, Salesforce, Slack, etc. are then accessible through this identity. This is the modern approach of Single Sign-On (SSO) convenient for users, easier to audit, and correspondingly dangerous if a single set of credentials is compromised.
This model also extends to communication between computers where non-human identities, or service accounts, have historically lived as ordinary user accounts with long, rarely rotated passwords, often shared by the team that owned the service and documented, if at all, in a forgotten wiki page. This is one of the weakest links in many IAM implementations, and it is literally what modern standards try to replace.
OAuth 2.0 and OpenID Connect let an application obtain a short-lived token on behalf of a user (the “Sign in with Microsoft” or “Continue with Google” buttons you see on SaaS products), SAML federations allow two organizations to trust each other’s identity providers for business-to-business access, and workload identities in Entra ID, AWS IAM roles, and Google Cloud service accounts remove the need to store passwords inside applications at all.
A concrete takeaway is that an IAM solution is almost never a single product: it can be a mix of Active Directory, a cloud identity platform like Entra ID, and a secrets manager for machine accounts. Idelaly, your ISO 27001 controls need to cover all of them.
Where IAM sits in ISO 27001
Being such an important concept in information security, access control touches the organizational (A.5), people (A.6), physical (A.7), and technological (A.8) controls in Annex A. The topics you need to cover are:
- Access control documentation that states how access is governed (A5.15, A7.2).
- A user lifecycle that covers joiners, movers, and leavers (A5.16, A6.5).
- Management of privileged accounts and utilities (A8.2, A8.18).
- Authentication mechanisms, including password and secret handling (A5.17, A8.5).
- Periodic review of access rights (A5.18).
- Segregation of duties (A5.3).
1. Start with documentation (A5.15, A7.2)
The first instinct of many organizations is to buy an IAM product before writing anything down. That is the wrong order. ISO 27001 asks you to establish an access control policy based on business and information security requirements (A.5.15 Access control). In practice, this is part of your information security (IS) procedures that answers four questions: who owns access decisions for each system (usually the business owner, not necessarily IT), on what basis access is granted (role-based is the default in most organizations, often with need-to-know and need-to-use addition), what the default permissions are for each role and what requires a separate approval, and how long accounts are allowed to remain inactive before they are disabled.
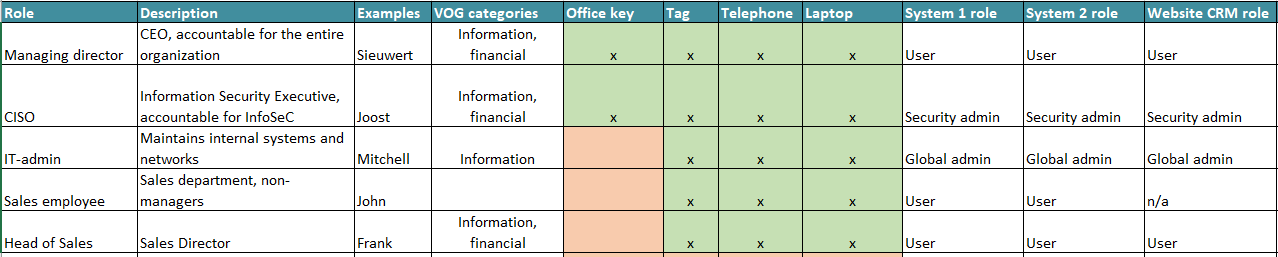
One way to implement them is by defining an access matrix with roles as rows, assets as columns and access level as values (see our template). The access matrix should include physical access to buildings and offices (A 7.2 Physical access).
2. Review the onboarding and offboarding process (A5.16, A6.5)
The biggest source of orphaned accounts is a broken handover between HR and IT. The control you need here is a documented process that is triggered (automatically) by HR events as part of an integrate identity lifecycle (A5.16 Identity management).
A practical pattern looks like this. When HR records a new hire, a ticket is raised to provision a baseline account with the role matching the new employee’s position. When someone changes role, a parallel ticket is raised to review and, importantly, to revoke the permissions that are no longer needed (A6.5 Responsibilities after termination or change). Removing requires someone to actively compare the old and new role. When someone leaves, accounts must be disabled on the last working day.
An auditor will sample people who joined or left in the last six months and trace the paper trail. If you cannot show and demonstrate these controls, this will not work well for the auditor, regardless of what you policy says.
3. Treat privileged access as a separate category (A8.2, A8.18)
Administrator accounts, service accounts, and break-glass accounts deserve their own category. The relevant ISO 27001 controls (A8.2, A8.18) can be translated into three practical measures. Administrators should have two accounts: a normal one for email and everyday work, and a separate administrator account used only for privileged tasks. Privileged sessions should be short-lived for a specific task. Service accounts must have named owners, and those owners must still be with the company otherwise this can become a vulnerability.
This is implementable by combining tracking the service accounts with the user roles in the access matrix, and documenting the process in the IS procedures.
4. Mange authentication mechanisms (A5.17, A8.5)
The most overused sentence in access policies is “users must choose a strong password”. Keep that in your rules and policies, but complement with additional measures like Two Step Verification (2SV) or Multi Factor Authentication (MFA). 2SV and MFA have become the de-facto baseline expectation of ISO 27001 (A.8.5). Managing this, however, is more nuanced.
If you cannot mandate MFA for any reason, mandate or recommend a password manager, both in IS procedures and staff rules (A5.17). You should mandate MFA whenever possible and especially for privileged or sensitive accounts like finance, root could or other admin accounts. A lot of IAM solutions have the option to use risk-based authentication whereby the zero-trust paradigm requires each access request for each system to be evaluated and, based on the risk of a given request, will challenge the user for authentication using a stronger method (like 2SV). More complex deployments, especially microservices in cloud architectures, require a secrets manager such as HashiCorp Vault or AWS Secrets Manager to hold API keys and certificates. As always, the measures should be proportionate to the risks.
A useful exercise with your IT team: list your top ten systems by sensitivity, and write down the authentication requirements for each. If they are all “username and password,” your authentication controls are not calibrated to risk.
5. Review access rights and document the changes (A5.18)
ISO 27001 explicitly requires organizations to review access rights at planned intervals (A.5.18). For most organizations, bi-yearly is a reasonable default, with quarterly reviews for privileged accounts and after any significant organizational change. The review must be performed by someone who can actually judge whether the access is still appropriate, like the business owner but not just the IT admin.
You can use the access matrix where you defined the roles and privileges, and a list of users with roles they currently have. The change can be documented as a meeting minute when this decision has been done, or more easily withing the same list of users but with a new entry per each review if done yearly or each six months. This is a common piece of evidence an ISO 27001 auditor will ask you to produce for Annex A access controls.
6. Separate sensitive duties (A5.3)
Finally, segregation of duties (A.5.3) is the control that prevents one person from both initiating and approving the same critical action. In practice this means, for example, that the developer who writes a production deployment script should not also be the person who approves the change request, and the employee who creates a supplier record in the ERP should not also be the one who releases a payment to that supplier.
This is easy to implement within the access matrix where conflicting duties are highlighted: the ISO-compliant minimum is to write the matrix down and enforce it in tooling wherever possible. Sometimes segregation is technically impossible, like in small teams, then compensating controls such as four-eyes review of logs are expected.
Closing thoughts
Implementing IAM controls for ISO 27001 is about upkeeping the six points above. Only then the choice of the tools matters. A good tool should help you out with implementing and demonstrating this due diligence. For those who whish to automate identity and access management at their organizations, we can support you with Vanta’s trust management platform to implement and run your ISMS. If you are setting up access controls in your organization and would like to see how this fits within the overall ISO controls, our full ISO 27001 guide on YouTube is the best place for a self-starter, while the full Annex A controls guide provides a more detailed resource.
Image credit: Photo by Buddy AN on Unsplash
Dr. Pavlo Burda is an IT consultant and researcher specializing in emerging cybersecurity threats and people analytics for security.