
GDPR, AI and ethics requirements for scientific research with personal data
| Pavlo Burda |
Artificial Intelligence
Privacy

Scientific research frequently involves collecting and analysing personal data, which brings researchers into direct contact with the GDPR and ethical responsibilities. Yet many researchers struggle to understand GDPR requirements for scientific research, which rules apply and how to implement them in practice.
GDPR requirements for scientific research
Scientific research often includes the processing of personal data. Think of a questionnaire where you want to collect data such as names, age, email addresses or more sensitive attributes like gender or private habits. When handling personal data, privacy regulations such as the GDPR, and principles ethical conduct must be taken into account throughout the data management process. However, it can be very challenging for researchers (and students) to follow the relevant procedures when designing and executing research tasks.
The GDPR is driven by a short number of principles that anyone processing personal data should apply. You should always follow the principles of the GDPR since the GDPR was always intended as practical regulation, more like traffic rules than complicated trade law. The following principles are important:
- You should be transparent. So if you do a a survey or social experiment, make sure you explain the survey or experiment clearly. People should know who made the survey, whether it is related to a this project or other project, the name and main topic of the project and which university leads the research.
- You should not collect more information than necessary. This means that you should not ask irrelevant questions (e.g. in a study on automatic cars, avoid asking age and gender, instead ask how many miles people drive or travel or how many years of driving experience they have). This also means that you only record audio and video when truly necessary and avoid asking personal stories or sensitive data such as medical history.
- You should only share data with reliable suppliers that your university has a data processing agreement with. In practice this means you should ask your lecturer or university colleagues which suppliers are approved and contracted by your university and avoid cloud based services for processing personal data. This is an interesting research topic in itself. If you are handling personal data, try to process it locally using libraries instead of relying on services
- Do not keep personal data longer than necessary. This is a challenging requirement since doing research requires you to keep your data for 10 years in case other researchers question your research. You should probably transcribe recorded interviews and delete the recordings and keep transcriptions. You should remove irrelevant personal details from the transcriptions or data files (anonymisation) or replace them with codes that are stored elsewhere (pseudonimisation).
- You should avoid collecting data about criminal background or activities, medical history, sexual preferences, ethnicity or religion in your computer science research. The GDPR described these characteristics as special and forbids the processing of special personal data except in some very specific cases and with additional measures in place. Please also take note that there are additional rules and guidelines for medical research that your professor probably does not know, such as the medical device regulation.
The key to good, ethical research is thus knowing your limitations, careful interview / experiment design, combined with good data management. You should therefore plan your research in a project proposal or plan. For larger research projects, it is often required to make a data management plan. Once you have a plan in place, follow your plan and pay attention to detail. E.g. it is better to ask for age in brackets since this is how you report it then to ask for exact date of birth.

Research integrity
The GDPR is not the first and not the only regulation that applies to scientific research. You should also study and always follow the general principles of Honesty, Scrupulousness, Transparency, Independence and Responsibility determined in the Netherlands Code of Conduct for Research Integrity. This is applicable to all Dutch universities.
In practice, this means you should report your methods as accurately as possible, refrain from making unfounded or exaggerated claims, describe the limitations of your results and, importantly, never falsify data. Indeed, a major concern in research is plagiarism: presenting others creative work as yours. Always cite the study behind an idea or fact you read somewhere, this way, you demonstrate your knowledge on the topic and readers can find your sources. When using the original author’s words, always use the quotation marks with the reference (“To be or not to be, that is the question”, Shakespeare).
If generative AI is permitted and you fail to acknowledge its use correctly, this is regarded as plagiarism. To a trained eye, it is possible to sense when a text has been generated with AI with no editing.
This extends to figures and even how you format the references. Plagiarism can also be unintentional, especially when using generative AI tools such as looking for relevant papers and references – gen AI can make mistakes even when just reformatting citation styles. Similarly, take great care in describing clearly our research efforts. For instance, when manipulating data with generated code, you need to double-check what the vibe-script does (do not ‘fire and forget’).
Be clear when describing what you have and what you have done. How did you get the data? How did you achieve the results? In case parts of research or data have to be kept confidential (e.g., when signing an NDA) you should respect the confidentiality while still providing a motivation. Transparency is important also when using gen AI tools: clearly state upfront what and how gen AI tools have been used in your thesis or research, perhaps, with an AI statement.
In research, avoid non-scientific considerations, e.g., marketing-style or opinionated description of results. This connects to being responsible and to to think that you do not operate in isolation. For example, when carrying out surveys or interviews you should acknowledge that your actions can have consequences for the individuals that are involved in your research, such as the risk of publishing personal data or sharing it with gen AI tools without anonymizing it first.
Following these principles is not only a moral duty, but concrete standards to follow. Failing to follow them has concrete negative consequence in the form of sanctions. Indeed, the Code of Conduct lists clear standards on what to do and what not to do along the design, execution and reporting phases of a research project. In the event of misconduct, like plagiarism or sharing personal data, there are concrete sanctions. On top of a reputational damage – in serious cases of plagiarism – the examination committees can decide to dismiss or expel from the institution the person concerned.
Additional Surf guidelines
For researchers interested in data management and privacy, the SURF Privacy Expertise Center published a practical guideline for researchers in higher education to comply with the GDPR. The guideline is a roadmap on how to properly manage personal data during the entire research lifecycle. One of the main highlight in the guideline is that research at universities falls under the special regime of the GDPR and Dutch AP (Autoriteit Persoonsgegevens) whereby (sensitive) personal data may be used for scientific research on the legal ground of general public interest.
According to article 6 of the GDPR the legal bases for processing personal data are consent, performance of a contract, legal obligation, vital interests, public task and legitimate interest. Scientific research thus falls under public task assigned to universities by law (Higher Education and Research Act). This means that you do not need to ask for permission to process personal data in your research as long as the research meets certain conditions:
- 1) research performed under the direction of a professor or lecturer
- 2) the research does not serve a primary private purpose
- 3) the research meets the relevant methodological and ethical standards (approved by the ethics committee) and
- 4) appropriate safeguards are in place (see below).
These conditions are typically met at all Dutch research and applied universities. Note that the ‘ethical consent’ remains relevant. The ethical consent is about asking to participate in research and is often reviewed by the same ethics committee of a university. Universities often provide instructions and templates about ethical consent.
The ‘public interest’ basis may also apply to sensitive data (e.g., salary, health or political beliefs), but here you would need to contact you university privacy contact point (additional security measures may be necessary). Public interest in not applicable to special personal data (e.g., medical data or religious beliefs) for which exceptions and stringent safeguards would need to apply, such as informed consent and strict measures to mitigate the higher risks.
In case the public interest basis is not applicable, you should consider using the ‘consent’ basis where you ask the permission of the involved person. However, you will need to do this in the right way (consent must be free, clear, informed and specific to the task).
A step-by-step procedures
Even if the the public interest basis applies, there must be appropriate safeguards of data protection. Specifically: lawfulness, propriety, transparency, purpose limitation, minimum data processing, accuracy, storage limitation, integrity and confidentiality. It is your duty to comply and demonstrate these principles for example by being transparent, explaining the voluntary nature of surveys, minimizing personal data use, avoiding special personal data and using EU based tools.
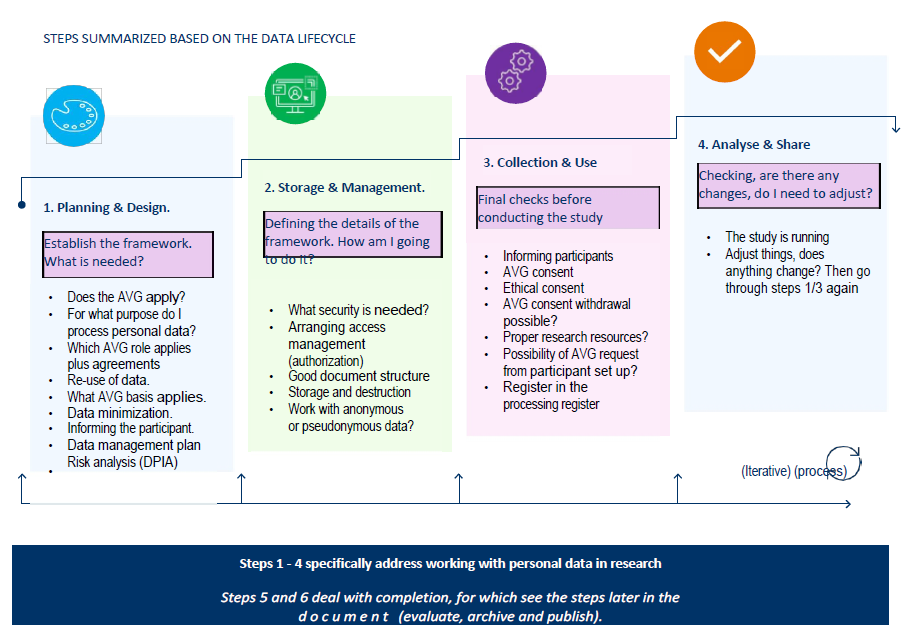
The guideline from SURF implements it nicely in a 6-step process along the typical data lifecycle :
-
Planning & Design – determine if GDPR applies (anonymous data does not), legal basis (e.g., public interest) and define purpose and roles (e.g., controller or processor); assess need for a DPIA, plan reuse, and think of how will you manage the data (e.g., where to store or host, how to delete and with whom to share).
-
Storage & Management – understand pseudonymisation vs. anonymisation, design a privacy-friendly folder/file structure and set retention periods; choose to host in EU/EAA countries and, depending on the sensitivity of data, evaluate appropriate security measures (e.g., encryption, backups).
-
Collection & Use – produce an ethical consent and check if the ethics committee needs to be informed, inform participants transparently (i.e., the survey is not mandatory); in case of using ‘consent’ as a basis, obtain and store the informed consent, set up a process for consent withdrawal, use secure research tools, and register the processing activity.
-
Analysis & Sharing – this is when you are working with the data; check whether to delete unnecessary data when the project changes or further anonymise or pseudonymise.
-
Evaluate & Archive – decide what to retain for integrity/replication vs. what to delete, clean up working environments, and align with institutional retention/destruction policies.
-
Publishing – ensure only anonymised (or appropriately restricted) data are shared (e.g., published in repositories), and that quotes or potentially identifying information are handled with care.
Following these steps will help you to bootstrap your research project quickly and compliant with the rules of the GDPR. You can download the guideline in Dutch here.
To deepen your understanding, explore our GDPR DPIA guidance and consider joining one of our privacy-focused trainings.
Source: figure Handreiking persoonsgegevens in onderzoek by SURF NL and cover photo by ODISSEI on Unsplash
Dr. Pavlo Burda is an IT consultant and researcher specializing in emerging cybersecurity threats and people analytics for security.